Rapid: Distributed Membership Service at Scale
May 24, 2020This article presents a summary of the paper by Lalith Suresh, Dahlia Malkhi, Parikshit Gopalan, Ivan Porto Carreiro, and Zeeshan Lokhandwala, which appeared in USENIX Annual Technical Conference 2018. I also presented this paper in the Distributed Systems Reading Group, a weekly public paper reading group hosted by Prof Murat Debirmas.
This paper primarily about membership in distributed systems in the presence of gray failures. While crash faults are relatively easy to detect and fix, gray failures often go undetected or take a long time to localize and fix.
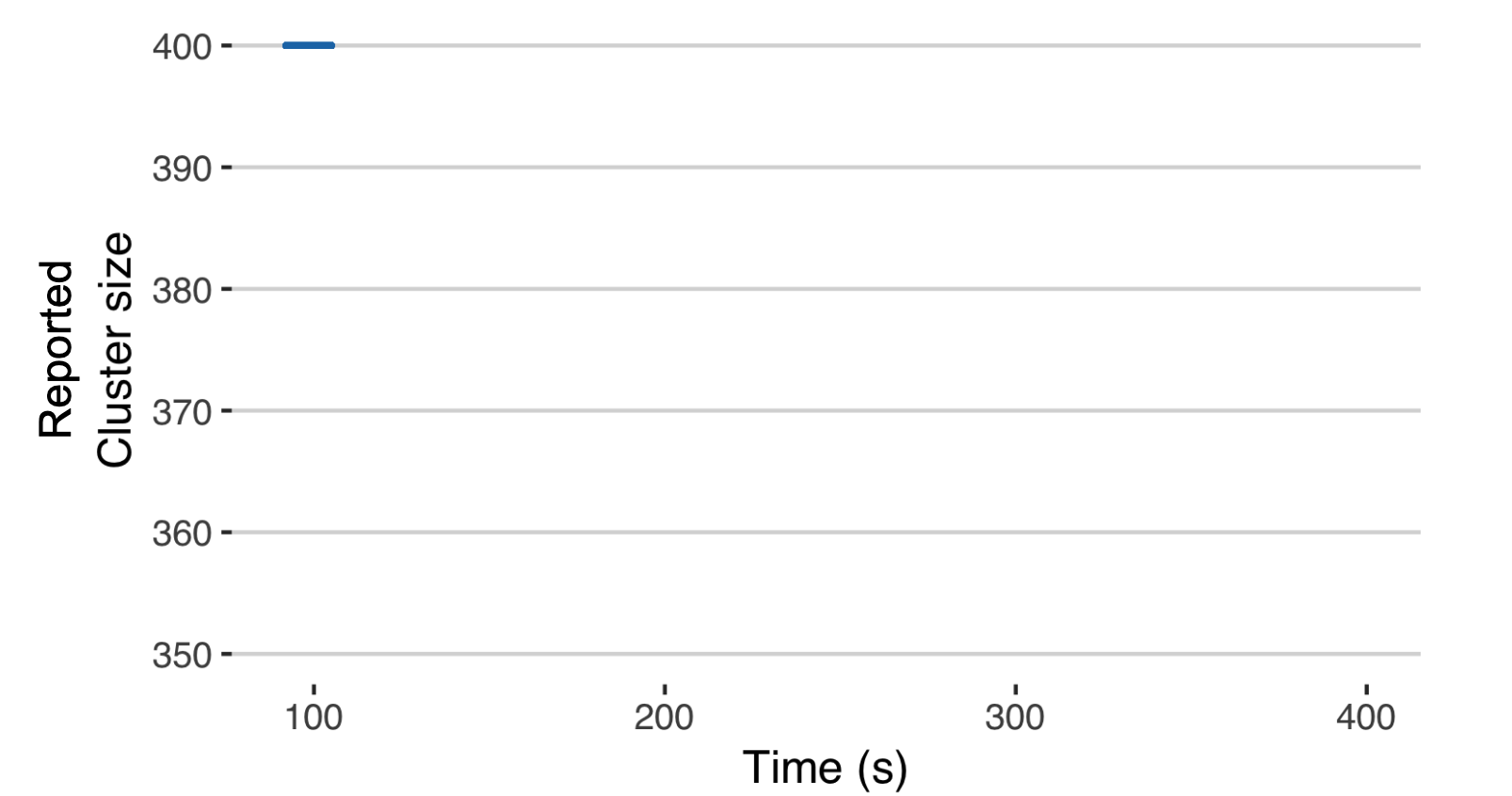
The authors whet our interests by setting up an experiment in a 400 node akka cluster which works on a gossip based membership model. They wait for the cluster to stabilize i.e. each node outputs the size of the members list.
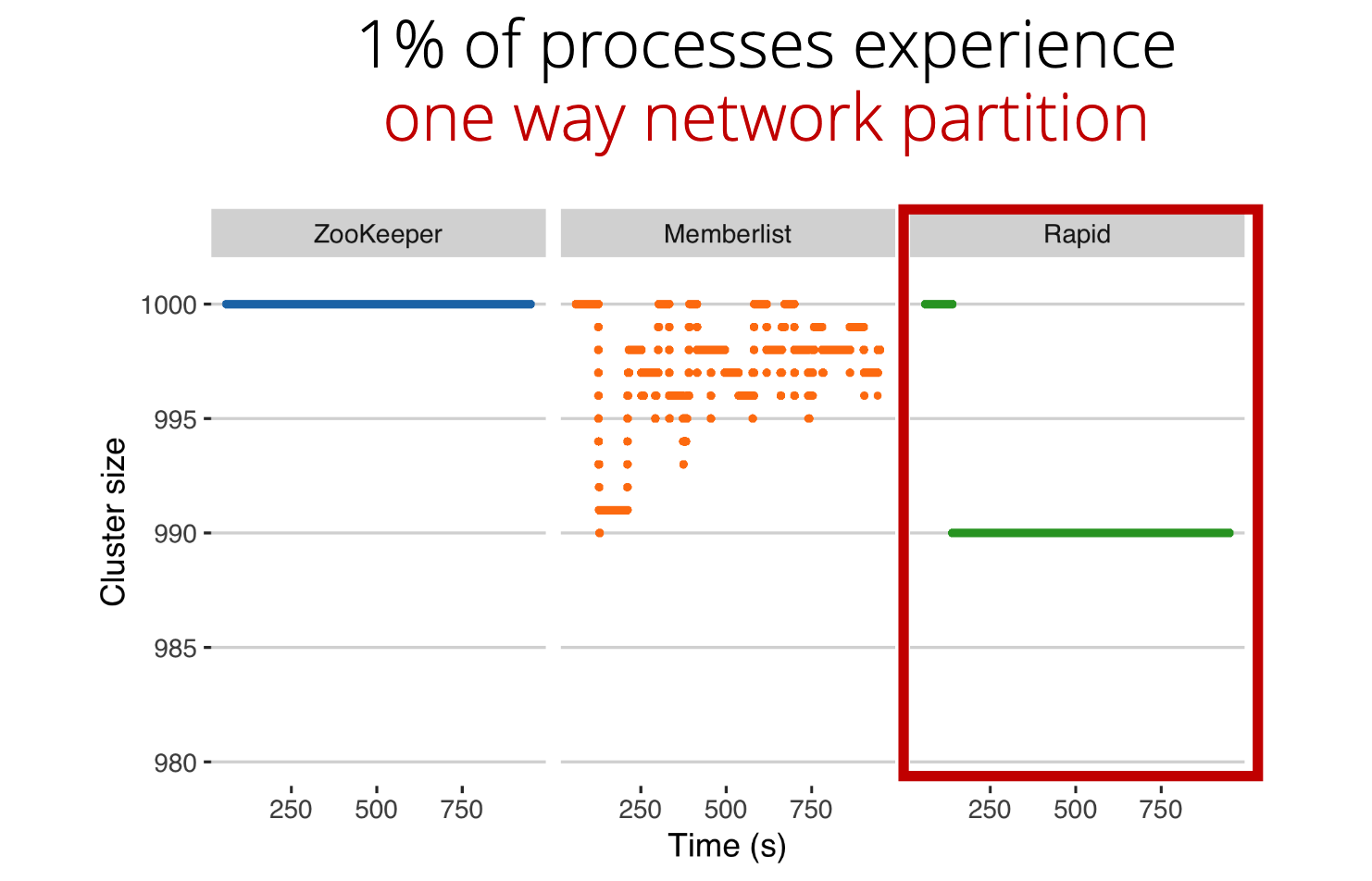
They now introduce packet-loss failures in 1% of nodes. This is where everything goes haywire. Due to the nature of the gossip based membership service, the correct nodes start to accuse each other and the membership view becomes unstable. At times, even some benign processes are removed from the membership view. This is problematic because expensive failure recovery and data migration services are triggered on view-change. In case of an unstable membership service this can lead to performance degradation and outages.
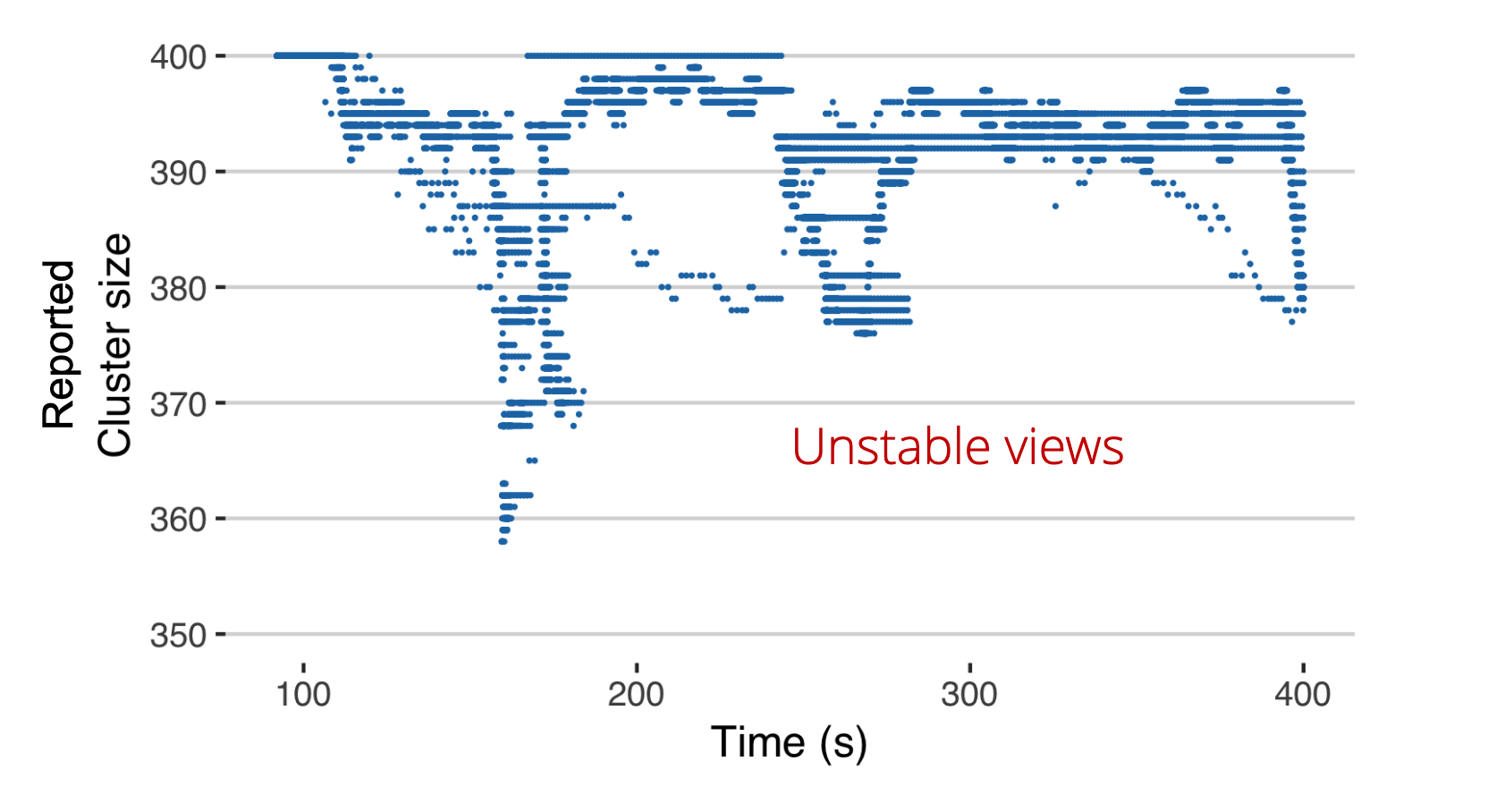
Additionaly, at any given time during the different nodes have different views of the membership. In the presence of inconsistencies, any service which utilize the membership service to get the ground truth about the cluster would not work properly.
Hence, this paper is about two features that the authors contend are inadequate in membership services today.
- Stability: robustness against asymmetric network failures, flip-flops, packet losses etc.
- Consistency: the processes see the same sequence of membership changes.
The solution which espouses these features is Rapid: A Distributed Membership Service at Scale. The service consists of three main components which follow a functional order.
- Monitoring Overlay.
- Membership change proposal.
- View-Change consensus
Monitoring Overlay
A monitoring overlay is formed with each node is monitored by K nodes. In this case a node that monitors is called an observer, and the observee is called a subject.
Construction of the overlay
The monitoring overlay is based on an expander graph. Expander graphs are graphs with a low degree and high connectivity. The authors use K pseudo-random rings to form an expander graph due to the fact that,
.. a random K-regular graph is very likely to be a good expander for
K$\geq$3.
Specifically, in a ring containing the full list of members, a pair of processes (o, s) form an observer/subject edge if o precedes s in a ring.
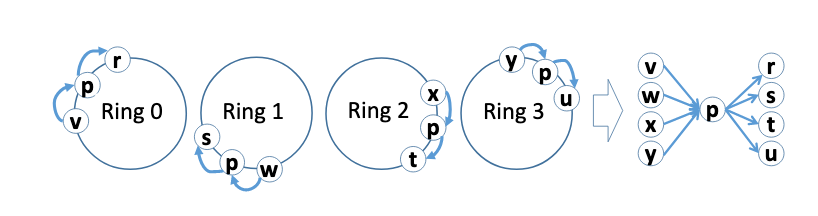
K is small (could be 10 even if the cluster size is 1000). The observers form a directed graph to the subjects. Rapid follows a template based model where the edge-failure detectors are provided by the user. These detectors could range from a simple heartbeat to observing TCP packets and application monitoring state.
Monitoring alerts like REMOVE (on detecting failure) and JOIN are disseminated by the observers using scalable best-effort broadcast. Furthermore, these alerts are irrevocable.
Multi-process cut detection
Each process maintains a M(o, s) which is set to 1 if an alert is received from an observer o about proces s. The alert tally for a subject s is tally(s) = M(*, s). A process would,
delay proposing a configuration change until there is at least one process in stable report mode and there is no process in unstable report mode.
A process s is considered to be in stable report mode by a process p if there exist at least H (high watermark) alerts about s, otherwise s is in an unstable report mode is in between L and H where 1 $\leq$ L $\leq$ H $\leq$ K.
Special cases
Processes s can get stuck in unstable mode if,
- An observer
oforsis itself faulty. In this case an implicit-alert is applied fromotos. - A process
shas a good connection with a subset of observers, but bad with others. In this case, ifsis in unstable mode for a certain time period, the observers echo the alert abouts.
After this stage each process have a new configuration to send to other processes.
View-change with consensus
A consistent configuration is achieved by treating the cut detected by each process from the previous stage as a proposal to a Fast Paxos instance.
The counting protocol itself uses gossip to disseminate and aggregate a bitmap of “votes” for each unique proposal. Each process sets a bit in the bitmap of a proposal to reflect its vote. As soon as a process has a proposal for which three quarters of the cluster has voted, it decides on that proposal.
Evaluation
Compared against Zookeeper (Logically centralized configuration service) and Memberlist (Gossip based membership).
Rapid provides,
- Better bootstrap times
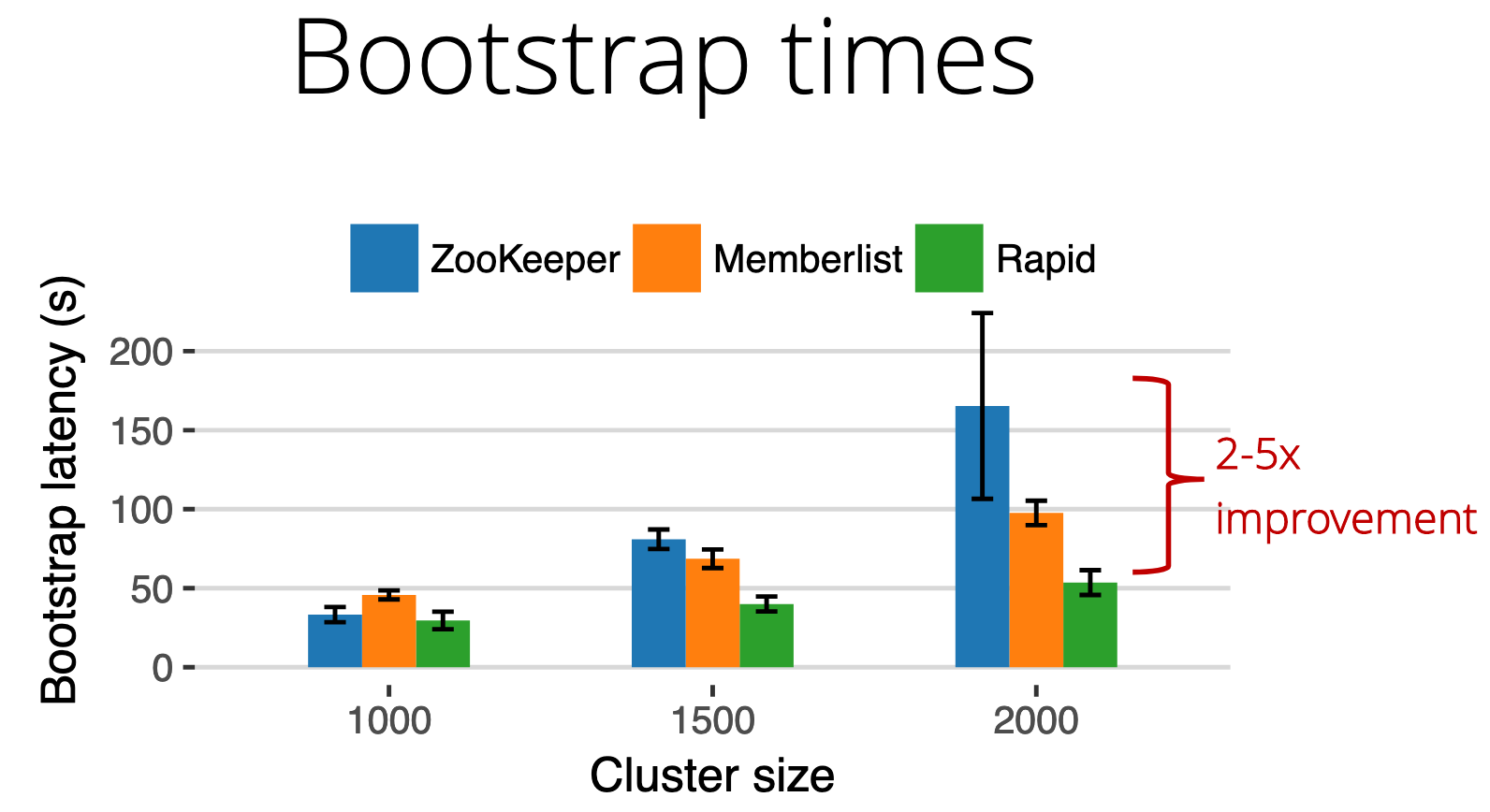
- Robustness in the presence of packet loss.
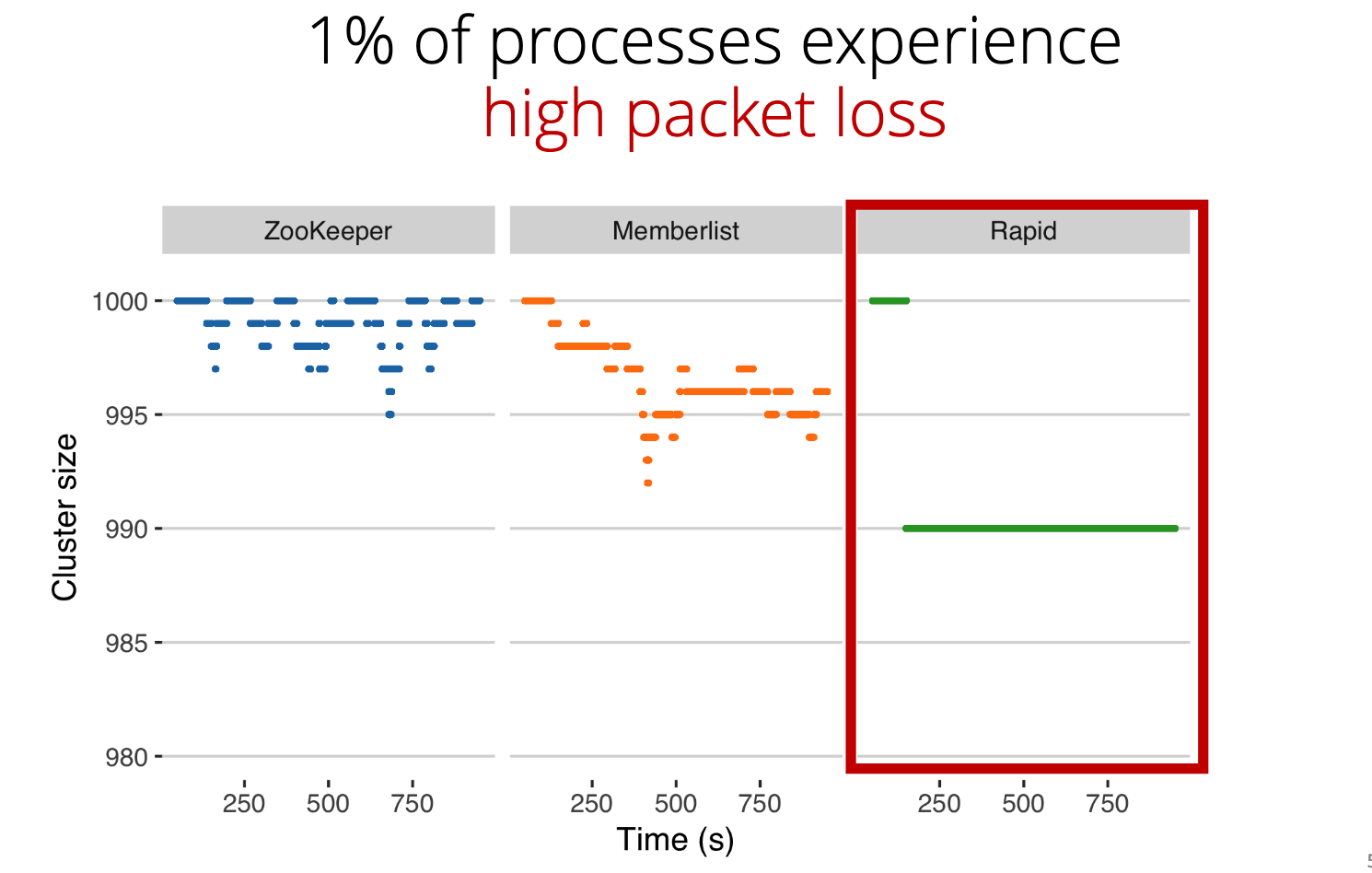
- , and in the case of network partitions